
[AI 리뷰] 사람처럼 보고 듣고 말하는 ‘GPT-4o’

본문

GPT-4o를 한마디로 표현하면 ‘보고 듣고 말할 수 있는 복합적 AI’이다. 실제로 오픈AI가 공개한 데모 영상을 보면 GPT-4o는 사람처럼 자연스럽게 대화하는 데다 유머 실력까지 갖추고 있다. 기존 AI와 대화는 딱딱할 뿐 아니라, 사람이 말한 내용을 AI가 듣고 나서 답하는 형태였는데 GPT-4o와 대화는 그야말로 물 흐르듯 자연스레 이어진다.
텍스트, 오디오, 이미지 및 비디오의 모든 조합을 입력으로 받아들이고 텍스트, 오디오 및 이미지의 모든 조합을 생성한다. 오디오 입력에 대해서 반응속도가 232밀리초 안에 응답할 수 있으며, 평균 320밀리초로 인간의 응답 시간과 비슷하다.
챗GPT가 말하는 와중에 사람이 끼어들어 말할 수 있고, 여러 명의 목소리도 동시에 인식한다. GPT-4o가 응답하는 데 걸리는 시간은 평균 0.32초로 사람과 거의 비슷한 수준으로 진화했다. 기존 GPT-4의 응답 속도는 5.4초였다.
기존 유료모델인 ‘GPT-4 Turbo’보다 2배 빨라졌고, 절반이나 저렴하다. GPT-4 Turbo는 한 번에 12만 8천 개의 ‘토큰(단어량)’을 처리할 수 있고, 월 구독료는 20달러인데 반해 GPT-4o는 ‘GPT-3.5’ 모델처럼 모든 사용자에게 무료로 제공되는데 단, 유료 구독자는 무료 이용자보다 5배 이상 더 많은 메시지를 사용할 수 있다.
GPT-4o 모델 이름에서 o는 옴니(omni)의 줄임말로 ‘모든 것’, ‘어디에나 있다’는 뜻을 포함하고 있다. 오픈AI가 GPT-4o를 ‘AI 종합판’이라고 부르며 자신감을 드러낸 데는 기존 그리고 타 모델과 차별화된 5가지 옴니 기능 때문이다. 아래는 5가지 옴니 기능을 설명한 아이콘이다.

- 텍스트, 이미지, 오디오 등 다양한 형식의 데이터를 처리할 수 있는 멀티모달(multi modal) 기능
- 이미지를 분석하고 설명하며 생성하는 강화된 비전(vision) 기능
- 실시간 웹 정보 검색을 통해 얻은 최신 정보를 기반으로 한 깊이 있는 답변 기능
- 외부 API(응용프로그램 인터스페이스)를 호출해 새로운 기능을 확장할 수 있는 펑션콜(function call) 기능
- 데이터 해석 능력을 바탕으로 한 비즈니스 인사이트 제공 기능 등이다.
주요 특징으로는 △향상된 언어 이해 능력: 이전 모델에 비해 더 높은 정확도로 텍스트를 이해하고 생성할 수 있다. 복잡한 문장 구조와 미묘한 뉘앙스까지 파악하여 자연스러운 대화를 이끌어낸다. △강화된 학습 데이터: 방대한 양의 최신 데이터로 학습된 GPT-4o는 최신 트렌드와 정보를 반영, 이를 통해 사용자에게 더욱 신뢰성 있는 정보를 제공한다. △다양한 언어 지원: GPT-4o는 다국어 지원 능력이 향상되어 다양한 언어를 능숙하게 처리하고 여러 언어 간 번역 능력도 뛰어나다. △맞춤형 응답: 사용자의 요구에 맞춘 개인화된 응답을 생성할 수 있어, 더 유연하고 적절한 대화가 가능하다.
다국어의 경우 기존에도 번역과 통역 기능은 있었지만 거의 즉각적으로 다른 언어 번역이 가능하도록 업그레이드됐다. 이에 따라 한국어 등 20개 언어를 토크나이저 압축으로 기능이 개선됐다. 아이언맨 영화에서 자비스를 장착한 수준으로 실시간 통역이 가능해 영어공부를 더 이상 할 필요가 없는 세상이 올지도 모른다.
GPT-4o에서 무엇보다 주목할 점은 AI가 카메라로 세상을 들여다본다는 점이다. 사람과 자연스럽게 대화가 가능해진 건 카메라를 통해 상대방 표정을 읽어내기 때문이다. 예를 들어, 사람이 수학 문제를 푸는 모습을 비춰주면 풀이 방법을 알려주거나, 컴퓨터 화면 속 코딩에서 잘못된 내용을 지적하는 것도 가능해졌다.
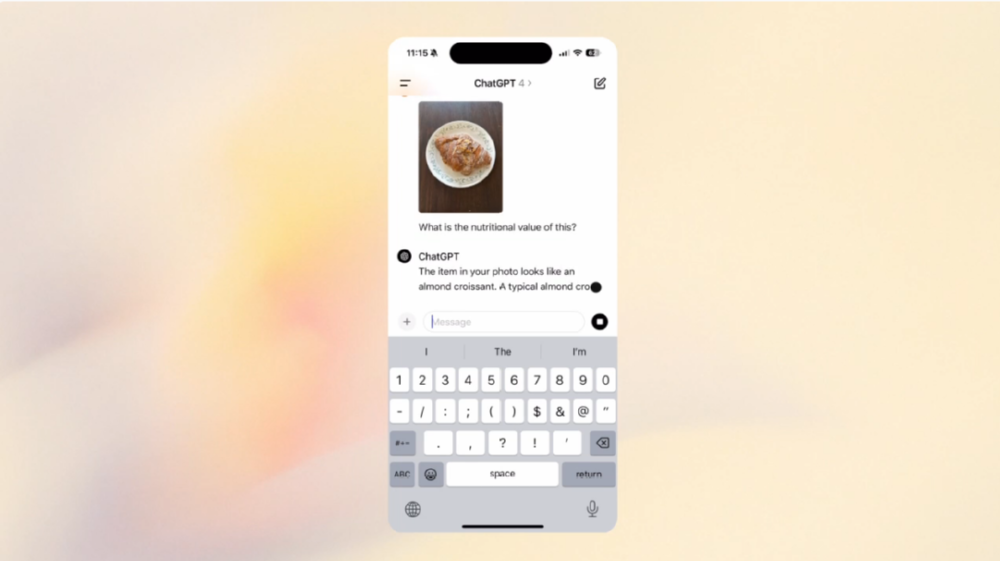
GPT-4o는 기존 'GPT-4' 'GPT-4V' 'GPT-4 터보' 등 기존 모델보다 더 빠르고 저렴하며 오디오와 비전 같은 입력으로부터 더 많은 정보를 유지하는 점에서 크게 개선됐다는 설명이다. 기술적으로는 기존에 대형언어모델(LMM)을 구동하기 위해 텍스트와 이미지, 음성 부분을 따로 담당하는 것을 넘어, 모델 3개를 하나로 통합했다.
이미지 인식과 음성 인식, 대답 등을 하나의 모델에서 추론함으로써 모든 대기 시간을 줄이고 사람이 하는 것과 동일한 수준으로 업그레이드됐다. 그 결과 입력된 소리에서 감정을 분석하여 대응할 수 있다. 예를 들어 거친 숨소리를 입력하면 '진정해, 긴장하지마' 라고 말해준다. 또한 데스크톱에서는 코딩을 함께 보면서 이 코딩에서는 어떤 부분을 고쳐야 하는지 음성으로 대화하면서 사람과 영상통화를 하면서 도움을 받는 듯한 느낌마저 준다.
기존 모델들은 여러 다른 모델들을 연결하고 오디오 및 비주얼과 같은 다른 매체를 텍스트로 변환한 후 다시 변환하는 방식을 사용했지만, 새로운 GPT-4o는 단일 모델에서 처음부터 멀티미디어 토큰으로 훈련, 텍스트로 변환하지 않고도 비전과 오디오를 직접 분석하고 해석할 수 있다는 것이다.
종합해보면 GPT-4o는 ‘보고 들으면서 말할 수 있는 복합 지능을 가진 AI’라고 할 수 있다. 인공지능 비서와 실제로 사랑에 빠지는 영화 Her가 점점 현실로 다가오고 있다.
GPT-4o는 모든 글로벌 이용자들에게 무료로 제공하지만, 기존 유료 이용자는 무료 이용자보다 5배 많은 질문을 할 수 있다. GPT-4o는 이날부터 사용 가능하며, 개발자는 이제 API에서 텍스트 및 비전 모델로 GPT-4o에 액세스할 수 있다. 앞으로 ChatGPT Plus 내에서 GPT-4o 알파 버전의 음성 모드 새 버전을 출시할 예정이다.
<ansonny@reviewtimes.co.kr>
<저작권자 ⓒ리뷰타임스, 무단전재 및 재배포 금지〉
추천한 회원
 TepiphanyI리뷰어
TepiphanyI리뷰어
김우선I기자의 최신 기사
-
[문화&이벤트 리뷰] [여행 리뷰] 포르투갈 포르투에서 크리스마스 ‘뱅쇼’ 축제 즐기기22초전
-
[공공] [교통] 기후동행카드, 경기 고양•과천까지 사용 가능해진다17시간 35분전
-
[문화&이벤트 리뷰] [요리 리뷰] 김장김치에 찰떡궁합 돼지고기 요리 레시피22시간 49분전
-
[IT] [AI] 대원씨티에스, ‘AI 동맹’ 굳건해졌다...노타 및 LG AI연구원과도 맞손24시간 36분전
-
[IT] [HR] 휴먼컨설팅그룹, 60억 자금 조달로 HR SaaS 개발 적극 투자2024-11-21
-
[IT] [PC] MSI, 대학 신입생 겨냥 비즈니스 노트북 출시2024-11-20
-
[기업리뷰] [여행 정보] 연말 휴가철 가성비 좋은 아시아 지역 여행지는 어디?2024-11-20
-
[IT] [보안] 사이버 공격 피해 83%는 중소기업2024-11-19
댓글목록0